

เคยสงสัยไหมว่า เว็บไซต์ประกาศรับสมัครงานอย่าง JobTopGun หาวิธีช่วยให้ผู้สมัครงานได้งานที่ใช่ได้อย่างไร คำตอบอยู่ในงาน SCBX Unlocking AI EP 9: Advancing ThaiLLM Development and Applications ที่ผ่านมานั่นเอง!
อ.ดร.เอกพล ช่วงสุวนิช จากภาควิชาวิศวกรรมคอมพิวเตอร์ คณะวิศวกรรมศาสตร์ จุฬาลงกรณ์มหาวิทยาลัย มาบรรยายเรื่อง Understanding Textual Embeddings: Applications in Retrieval and Recommendation และเล่าประสบการณ์ที่เคยฝึกฝนและพัฒนา LLM อย่างไรบ้าง โดยมีกรณีศึกษาคือ JobTopGun นั่นเอง

ดร.เอกพล บอกว่ามนุษย์เรามีความสามารถในการตีความ เรารู้ว่า ประโยคไหนมีความหมายเหมือนหรือใกล้เคียงกับประโยคไหนบ้าง เช่น A Little Girl Seems to be Very Sad มีความหมายใกล้เคียงกับ The Little Child is Far From Being Happy
แต่เมื่อจะพัฒนา LLM ก็ถือเป็นความท้าทายเหมือนกันว่า เราจะต้องป้อนข้อมูลอย่างไรให้คอมพิวเตอร์เข้าใจความหมายของประโยคที่เขียนไม่เหมือนกัน แต่ความหมายเหมือนหรือใกล้เคียงกันได้ด้วย
ดร.เอกพล ยกตัวอย่างว่า เขาเคยฝึกระบบของ JobTopGun เว็บไซต์ประกาศหางานที่เปิดโอกาสให้ผู้คนเอาเรซูเม่สมัครงานมาอัปโหลดในเว็บไซต์ หน้าที่ของเขาคือทำอย่างไรก็ได้เพื่อหาทางจับคู่เรซูเม่ต่างๆ ให้เจอตำแหน่งงานที่เหมาะสมให้ได้
เขาจึงฝึกให้ปัญญาประดิษฐ์อ่านเรซูเม่ของผู้สมัครงาน และ Job Description ของแต่ละงานจากแต่ละองค์กร จนมันรู้จักลักษณะงานที่เหมาะสมของแต่ละคน จนเข้าใจว่าถ้าเจอว่าประวัติของคนๆ นี้ต้องไปทำงานแบบไหน กับบริษัทใด
สำหรับเทคนิคในการเรียนรู้ที่ใบ้สอนปัญญาประดิษฐ์คร่าวๆ จะมี 2 แนวคือ Sparse Embeddings และ Dense Embedbings
1. Sparse Embeddings หมายถึงการให้ Machine Learning อ่านหนังสือแล้วนับว่าหนังสือเหล่านี้มี Keyword อะไร เยอะแค่ไหนบ้าง เช่น หนังสือของวิลเลียม เชกสเปียร์ มีคำว่า Battle กี่คำ หรือมีคำว่า Soilder กี่คำ เป็นต้น แล้วเอาผลที่ได้ไปวิเคราะห์ต่อ
ข้อดีของ Sparse Embeddings คือใช้งานง่าย เข้าใจง่าย แต่ก็มีข้อควรระวัง เช่น บางกรณีอาจไม่เจอคำที่ต้องการให้นับ และบ่อยครั้งคอมพิวเตอร์อาจมองข้ามคำที่มีความหมายเดียวกัน แต่ไม่ใช่คำเดียวกัน ดังนั้นอาจต้องเปลี่ยนจากการนับจำนวนครั้ง เป็นการนับเปอร์เซ็นต์ หรือความถี่แทนว่าเจอคำนี้บ่อยแค่ไหน
2. Dense Embedbings ป้อนข้อมูล หรือ Input สำหรับ Deep Learning แล้วแปลงค่าสิ่งต่างๆ ออกมาเป็นตัวเลข หากเลขไหนเหมือนกัน หรือใกล้เคียงกัน หมายความว่าสามารถจับคู่สิ่งๆ นั้นกันได้ง่าย
ดร.เอกพล เล่าว่านี่คือวิธีการที่เขาสอนให้ Machine Learning ของ JobTopGun ได้เรียนรู้วิธีอ่านเรซูเม่ของผู้สมัครงาน โดย AI จะแปลงค่าเรซูเม่, Job Description หรือประกาศรับสมัครงานออกมาเป็นตัวเลข แล้วหากเลขนั้นเทียบกันแล้วได้ค่าใกล้เคียงกันหรือเท่ากัน ก็บ่งชี้ว่าเรซูเม่ของผู้สมัครงานเหมาะกับงานนั้นที่เปิดรับสมัครไว้นั่นเอง
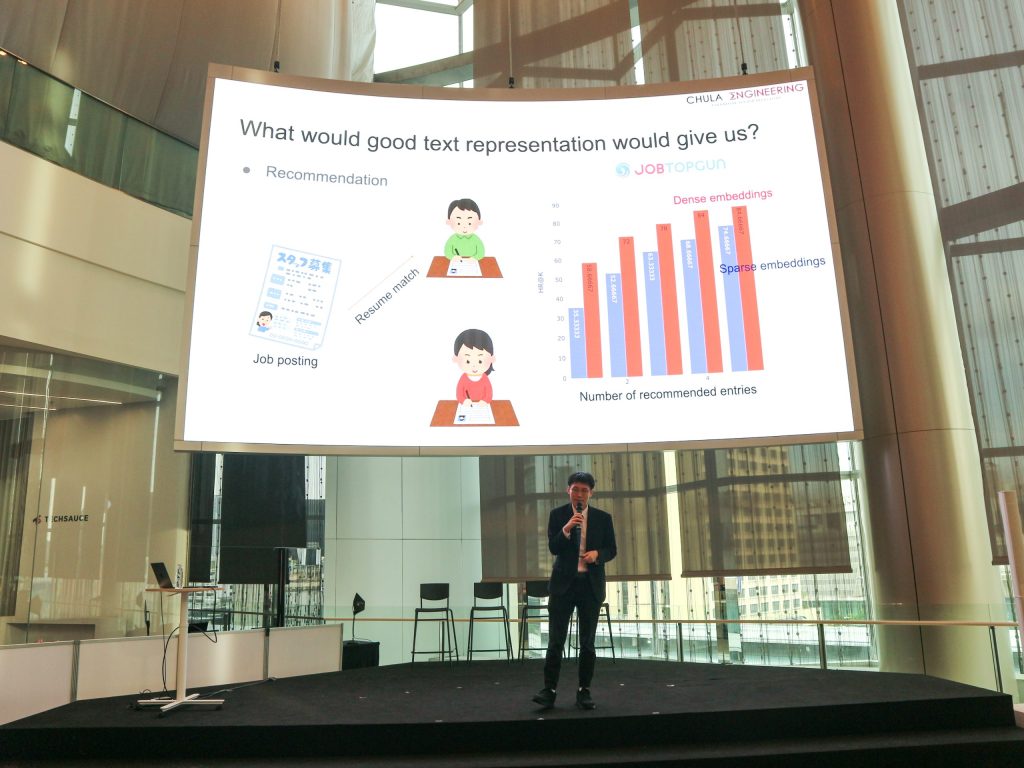
ทั้ง Sparse และ Dense Embedbings ต่างมีข้อดีและข้อเสียแตกต่างกันไป ก่อนใช้ต้องดูว่ากรณีไหนที่ควรใช้ Sparse กรณีไหนควรใช้ Dense หรือจะนำมาใช้ร่วมกัน เพื่อดึงข้อดีของทั้ง 2 วิธีออกมาให้เต็มที่
ขอเพียงเข้าใจคอนเซ็ปต์ และวิธีการทำงาน ดร.เอกพลมั่นใจว่า เราจะสามารถพัฒนาสิ่งที่น่าสนใจได้อีกมากมาย เพื่อยกระดับการทำงานของตัวเองและองค์กรต่อไป





